Breaking News


Popular News


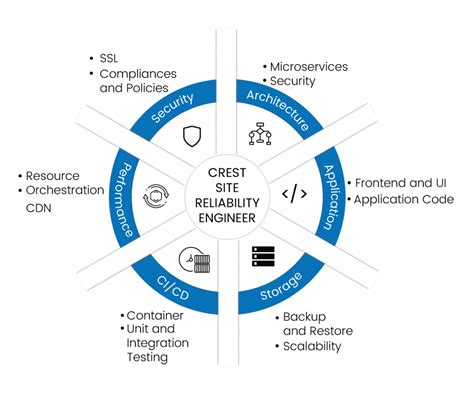
Discover the essential SRE tools and technologies for efficient site reliability engineering, including monitoring systems, automation, and incident management.In the world of modern technology, site reliability engineering (SRE) has become an essential focus for businesses striving to provide reliable and efficient online services. SRE focuses on utilizing various tools and technologies to ensure the seamless operation of websites and applications, ultimately enhancing the user experience. In this blog post, we will explore the fundamental aspects of SRE tools and technologies, including their significance and impact on today’s digital landscape.
We will begin by delving into an introduction to SRE tools, providing an overview of their purpose and functionality. Next, we will explore key SRE technologies that are widely used in the industry, highlighting their importance in achieving reliability and scalability. Furthermore, we will discuss monitoring and alerting systems, emphasizing their role in proactively identifying and addressing potential issues. Additionally, we will examine automation and configuration management tools, as well as the critical role they play in streamlining operations. Finally, we will explore incident management and response strategies, outlining the best practices for effectively mitigating and resolving disruptions. Join us as we embark on a comprehensive journey through the realm of SRE tools and technologies.
Contents

Site Reliability Engineering (SRE) is a discipline that incorporates aspects of software engineering and applies them to infrastructure and operations problems. SRE is all about creating a scalable and reliable software system. SRE tools are essential to achieving this goal.
Some key SRE technologies include monitoring and alerting systems, automation and configuration management, and incident management and response. These tools and technologies play a crucial role in managing and maintaining complex systems at scale.
Monitoring and alerting systems like Prometheus and Grafana help SRE teams to monitor their infrastructure and applications, detect issues, and alert the appropriate teams in a timely manner. Automation and configuration management tools like Ansible and Puppet enable SREs to automate repetitive tasks and manage infrastructure as code, increasing efficiency and reducing errors. Incident management and response tools like PagerDuty and OpsGenie help SRE teams to effectively respond to incidents, minimizing downtime and customer impact.
In addition to these tools, SREs also utilize other technologies such as logging and tracing tools, testing and deployment tools, and collaboration and communication tools to build and maintain reliable systems.

Site Reliability Engineering (SRE) is a discipline that incorporates aspects of software engineering and applies them to infrastructure and operations problems. Key SRE technologies play a critical role in maintaining reliability, scalability, and performance of systems. These technologies are essential for ensuring that services are running smoothly and able to meet user demands.
One of the key technologies in SRE is monitoring and alerting systems. These systems allow for continuous monitoring of the health and performance of infrastructure and applications. They provide real-time insights into the system’s behavior and can alert SRE teams to potential issues or anomalies. By using monitoring and alerting systems, SREs can proactively address any issues before they impact users.
Another important aspect of SRE is automation and configuration management. Automation tools help streamline repetitive tasks, reduce human error, and improve efficiency. Configuration management tools enable SREs to consistently manage and configure infrastructure, ensuring that changes are deployed in a controlled and predictable manner.
In addition to monitoring and automation, effective incident management and response tools are crucial for SRE teams. These tools allow for efficient communication, collaboration, and coordination during incidents. They enable SREs to identify, prioritize, and resolve incidents, minimizing the impact on users and maintaining service reliability.
Overall, key SRE technologies are essential for building and maintaining reliable systems. By leveraging these technologies, teams can effectively monitor, automate, and respond to incidents, ultimately improving the reliability and performance of their services.

Site Reliability Engineering (SRE) teams rely heavily on monitoring and alerting systems to ensure the smooth operation of their services. These tools provide real-time visibility into the performance and availability of applications, allowing engineers to proactively identify and address potential issues before they impact users. Monitoring tools such as Prometheus, Grafana, and Datadog enable SREs to collect and visualize key metrics, such as CPU usage, memory consumption, and network traffic, across their infrastructure.
Alerting systems play a crucial role in SRE by enabling teams to define thresholds and conditions that trigger notifications when performance metrics deviate from expected values. This allows SREs to respond quickly to incidents and minimize potential downtime. Tools like PagerDuty, Opsgenie, and VictorOps provide powerful alerting capabilities, including on-call schedule management, escalation policies, and incident response workflows.
In addition to monitoring and alerting tools, SRE teams also leverage logging and tracing systems to gain deeper insights into the behavior of their applications. Logging tools like ELK Stack and Splunk enable SREs to centralize and analyze application logs, while distributed tracing systems such as Jaeger and Zipkin help teams understand the flow of requests and identify performance bottlenecks.
Overall, monitoring and alerting systems are essential components of the SRE toolkit, allowing teams to maintain high levels of reliability and availability for their services.

Automation and Configuration Management are crucial aspects of Site Reliability Engineering (SRE) that help in ensuring the smooth and efficient running of systems and applications. Automation refers to the process of automating repetitive tasks and processes, reducing manual effort and improving efficiency. Configuration Management, on the other hand, involves managing and controlling the configuration of systems and applications to ensure consistency and reliability.
In SRE, the use of automation tools such as Ansible, Puppet, and Chef is common to automate tasks such as provisioning, configuration, and deployment of infrastructure and applications. These tools allow SRE teams to define infrastructure as code, reducing the risk of errors and inconsistencies, and enabling rapid and consistent deployment of changes.
Additionally, configuration management tools like Terraform and SaltStack help SREs in managing and maintaining the configuration of infrastructure and applications. These tools enable SRE teams to define and manage infrastructure resources using code, leading to improved scalability, reliability, and repeatability.
Overall, Automation and Configuration Management play a significant role in the smooth functioning of systems and applications, and are essential components of SRE practices that contribute to reliability, scalability, and efficiency.

Incident management and response are crucial aspects of site reliability engineering, as they involve dealing with unexpected issues that may disrupt the normal functioning of a system. When an incident occurs, it’s important to have a well-defined process in place for identifying, analyzing, and resolving the issue in a timely manner.
One of the key tools used for incident management and response is a monitoring and alerting system, which helps to detect and notify the team about any abnormal behavior or performance degradation in the system. This allows the team to quickly respond to the incident and mitigate its impact on the overall system.
Another important aspect of incident management is the use of automation and configuration management tools. These tools help in automating the response process for certain types of incidents, allowing the team to address the issue more efficiently and consistently.
Additionally, having a well-defined incident management and response process is essential for ensuring that the team knows exactly how to handle various types of incidents, and can quickly and effectively respond to minimize the impact on users and the system as a whole.

What is Site Reliability Engineering (SRE)?
Site Reliability Engineering is a discipline that incorporates aspects of software engineering and applies them to infrastructure and operations problems. SRE focuses on creating scalable and reliable software systems.
What are some popular Site Reliability Engineering tools?
Some popular Site Reliability Engineering tools include Prometheus, Grafana, Datadog, ELK stack, Kubernetes, Docker, Terraform, and Ansible.
How does Site Reliability Engineering differ from DevOps?
Site Reliability Engineering (SRE) focuses on building and maintaining scalable and reliable systems, whereas DevOps focuses on integrating and automating the processes between software development and IT teams.
What are the key principles of Site Reliability Engineering?
The key principles of Site Reliability Engineering include embracing risk, service level objectives (SLOs), error budgets, monitoring, change management, and automation.
What are some challenges faced in Site Reliability Engineering?
Challenges in Site Reliability Engineering include managing complex distributed systems, ensuring high availability, balancing feature development with reliability, and dealing with unexpected incidents.
How do Site Reliability Engineers use monitoring tools?
Site Reliability Engineers use monitoring tools to track the health and performance of systems, identify issues, set alerts for potential problems, and analyze trends to make data-driven decisions.
What are some best practices for Site Reliability Engineering?
Some best practices for Site Reliability Engineering include automating repetitive tasks, conducting blameless postmortems, defining and tracking service level indicators (SLIs) and SLOs, and continuously improving systems through iteration.







